Projects
A Farewell to Arms
- Online Machine Learning Framework for Sponsored Ads, Crowd Sourcing, Hyperparameter Tuning etc.
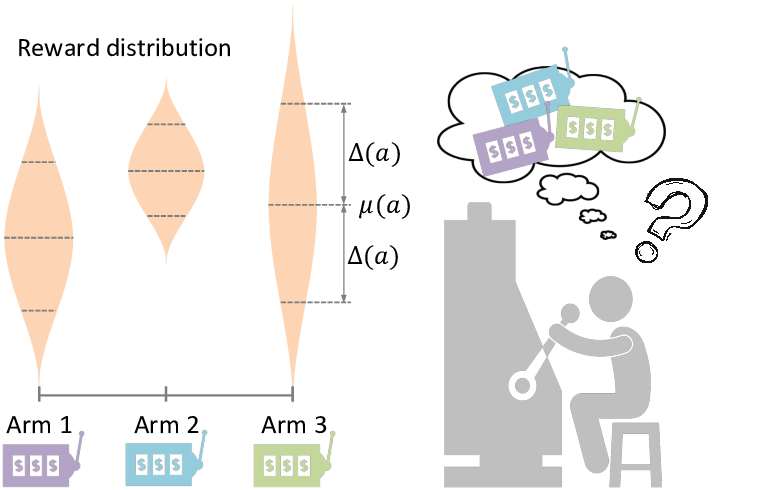
Tags: Online Machine Learning, Reinforcement Learning, Algorithms.
This work introduces a new Online Machine Learning framework "Farewell to Arms" named after Hemingway's novel of the same name. Since, the action
space of our setting is referred to as Arms and the learning agent (algorithm) can decide to give up on an action
without even completing ("like bading a Farewell"). This work address several of the real world applications
in the areas of Sponsored Ad search, Crowd Sourcing, Hyperparameter tuning, Effecient attention dependent computational advertisement which required a
new framework to design efficient and effective Online Learning Algorithm.
Summary: We consider a sequential decision-making
problem where an agent can take one action
at a time and each action has a stochastic
temporal extent, i.e., a new action cannot
be taken until the previous one is finished.
Upon completion, the chosen action yields a
stochastic reward. The agent seeks to maximize its cumulative reward over a finite time
budget, with the option of "giving up" on a
current action - hence forfeiting any reward
- in order to choose another action. We cast
this problem as a variant of the stochastic
multi-armed bandits problem with stochastic
consumption of resource. For this problem,
we first establish that the optimal arm is the
one that maximizes the ratio of the expected
reward of the arm to the expected waiting
time before the agent sees the reward due to
pulling that arm. Using a novel upper confidence bound on this ratio, we then introduce an upper confidence based-algorithm,
Wait-UCB, for which we establish logarithmic, problem-dependent regret bound which
comparing Wait-UCB against the state-ofthe-art algorithms are also presented.
has an improved dependence on problem parameters compared to previous works. Simulations on various problem configurations.
Linear Bandits
- Applying Online Machine Learning Algorithm for Bandits on Linear Generalization
Tags: Online Machine Learning, Reinforcement Learning, Algorithms.
This work focuses on applying Thompson Sampling - an Online Learning algorithm approach, for Linear
generalization setting on any sequence of states observed. The Thompson Sampling
approach proposed by Aditya Gopalan uses Gaussian prior and Gaussian likelihood.
The results showed that it reduces to Follow the Perturbed Leader(FPL) as in Kalai
et al. (2005) with a Gaussian noise as supposed to the exponentially distributed
noise. The regret bound for the Thompson Sampling Gaussian algorithm and its
proof is briefly covered in this note by combining all the relevant information.
Online Machine Learning Framework for Budgeted Bandits with Graphical Feedback.
- Most Efficient Online Learning Algorithm for Sponsored Ads, Attention based Computational Advertisement
Tags: Online Machine Learning, Reinforcement Learning, Algorithms.
This work further improves the Farewell to Arms (F2A) framework by incorporating
additional feedback (information observable to the algorithm) and develops the most efficient Online Machine Learning algorithms with
theoretical guarantees.
Summary
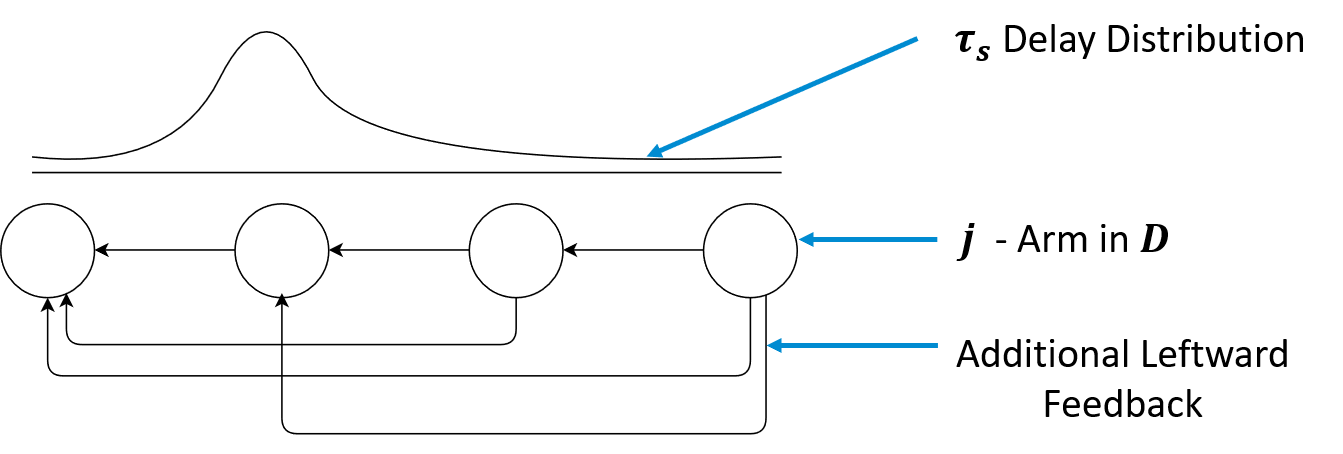
We study the problem with additional feedback, more than the mere bandit feedback, where the agent observes the reward
of the actions having shorter waiting time; we call this type of feedback "leftward
chain feedback". The figure below shows the action space in circles and the information received by the algorithm in arrow marks.
For this problem with additional feedback, we develop a novel upper
confidence bound-based algorithm, Wait-2 Learn UCB, which guarantees logarithmic,
problem-dependent regret bound.
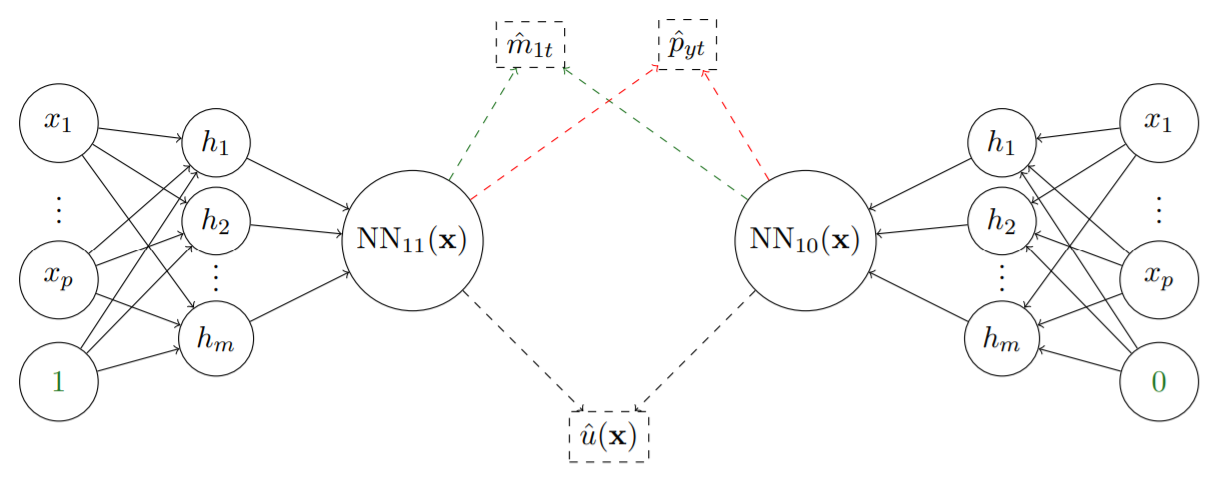
CausalNet
- Deep Learning based PyTorch Library for Causal Inference
Tags: Deep Learning, Causal Inference, PyTorch Library.
Uplift is a particular case of conditional treatment effect modeling with binary outcomes. Such models deal with cause-and-effect inference for a specific factor, such as a marketing intervention or a medical treatment.
This library implements the proposed (twin neural networks for uplift modeling).
This architecture allows to jointly optimize the marginal probabilities of success for treated and control individuals and the underlying model is a generalization of the uplift logistic interaction model.
We modify the stochastic gradient descent implementation to allow for structured sparse solutions (pruning). Each step of the training, it proceeds to update the model parameters in the direction of the gradients to minimize the uplift log-loss.
Both structured and unstructured pruning can be used to regularize the model.
The model supports numpy arrays int or floats for data ingestion.
The goal of this library is to make the twin-causal-net implementation accessible to practitioners through a few lines of code, following the scikit-learn syntax.
Attack sensing Recommendation system
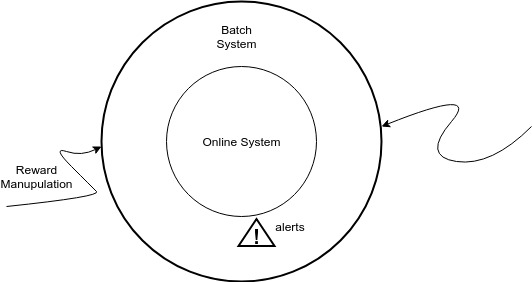
Tags: Reinforcement Learning, Recommendation System, Robust Algorithm.
We stimulate a attacks scenario where an adversary attacks a recommendation system by manipulating the reward signals to control the actions chosen by the system. For our attacking scenario, we took
the famous Movie Lens Dataset and applied collaborative filtering to withhold the behaviour of the algorithm. The algorithm is able to detect the
attack when it deviates from certain threshold and intimates the alert sign.
Improving stack Exchange Network using Data Science Techniques
Tags: Natural Language Processing, Dimensionality Reduction, Unsupervised Learning.
Dataset: Stack Exchange Data Dump
The StackExchange data dump was analyzed and two major data-driven features to improve its overall operation were proposed. A successful Exchange of knowledge happens when posters ask good questions and the asked question reaches the relevant Scholar. However, some new novice users who ask questions creates some unrelated tags for that questions. To solve this problem, First, we created meta-tags for each question by projecting this question in a high dimensional space and finding correct tags by applying Unsupervised learning algorithm. Second, we found related posts for unique tags - a feature which is missing in the current live version of StackExchange - that could be instantly suggested to the posters. Third, a discussion on building a Virtual Title Assistant to aid new users to better ask questions was made, On further analysing the data, we found that the initial form of the title itself does not seem to impact the overall user experience. *All these proposals are made with emphasis on Data Modelling and Visualization.
Uncovering inflammatory Russian Troll Tweets on 2016 US
Tags:Natural Language Processing, Custom Word Embedding, Dimensionality Reduction
Data: Russian Troll Tweets [blog]
Technologies: Tensorflow, Tensorboard, NLTK, Gensim-Word2Vec, Python etc.
During the 2016 US presidential election there was said to be evidence of foreign interference by means of propaganda. The disinformation was allegedly spread over a number of social media platforms including twitter. As such it was a opportunistic to apply the techniques of text analysis to try and uncover evidence of this tampering. The preprocessing of the dataset involve procedures like stemming, lemmatization along with the removal of http links, non-English words, xml tags, etc. This corpus of text data was then used to train a custom embedding (Word2Vec model) having 300 neurons in the hidden layer giving us a 300 Dimension vectors. t_SNE was used to reduce the dimensions to 2D for the sake of Visualization. An indepth Bias analyses was carried out comparing the pre-trained Network to the Custom embedding in both positive and negative tone.
Reddits hyperlink
Tags: Graphs, Graphical data modelling, Dimensionality Reduction.
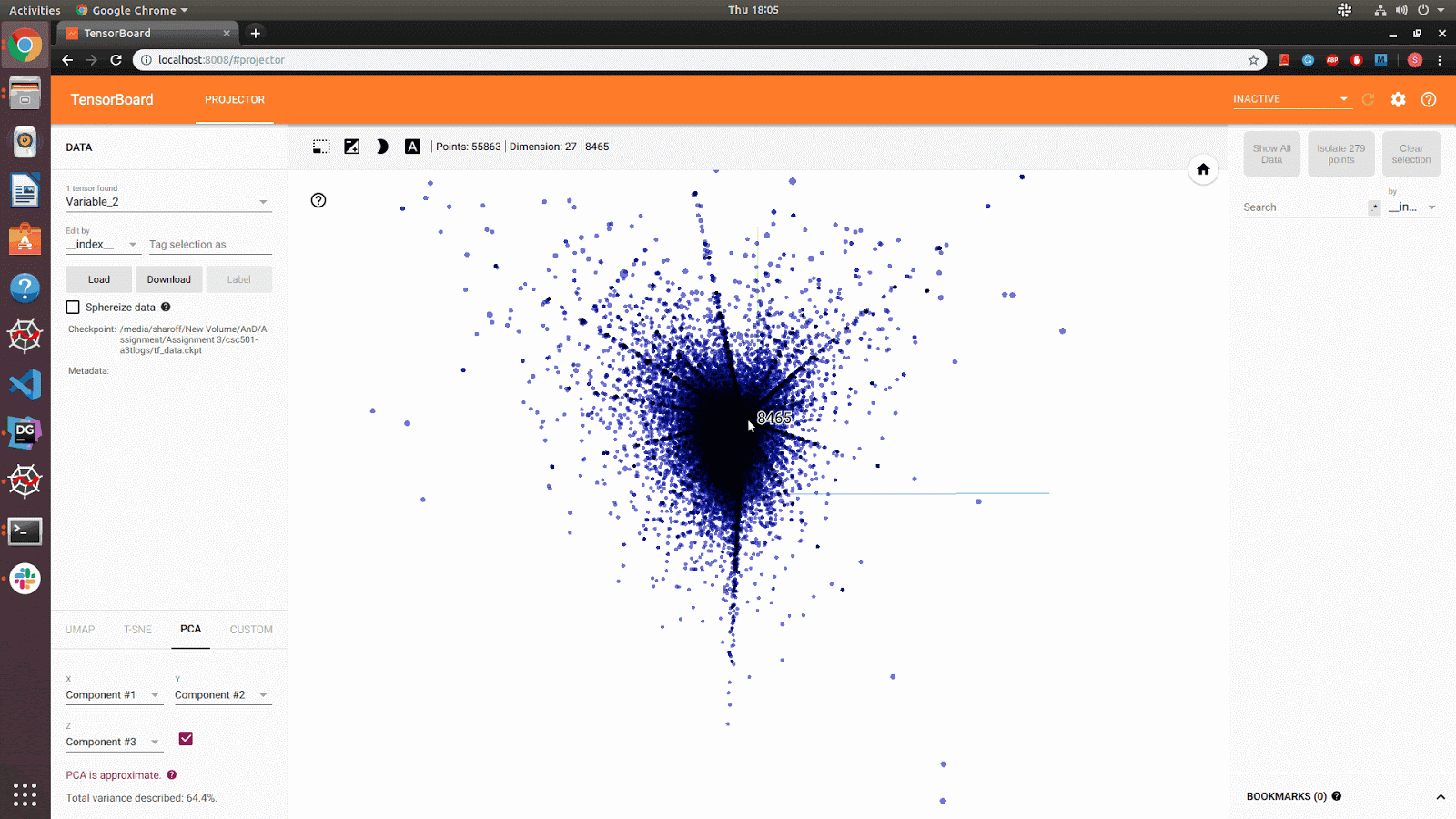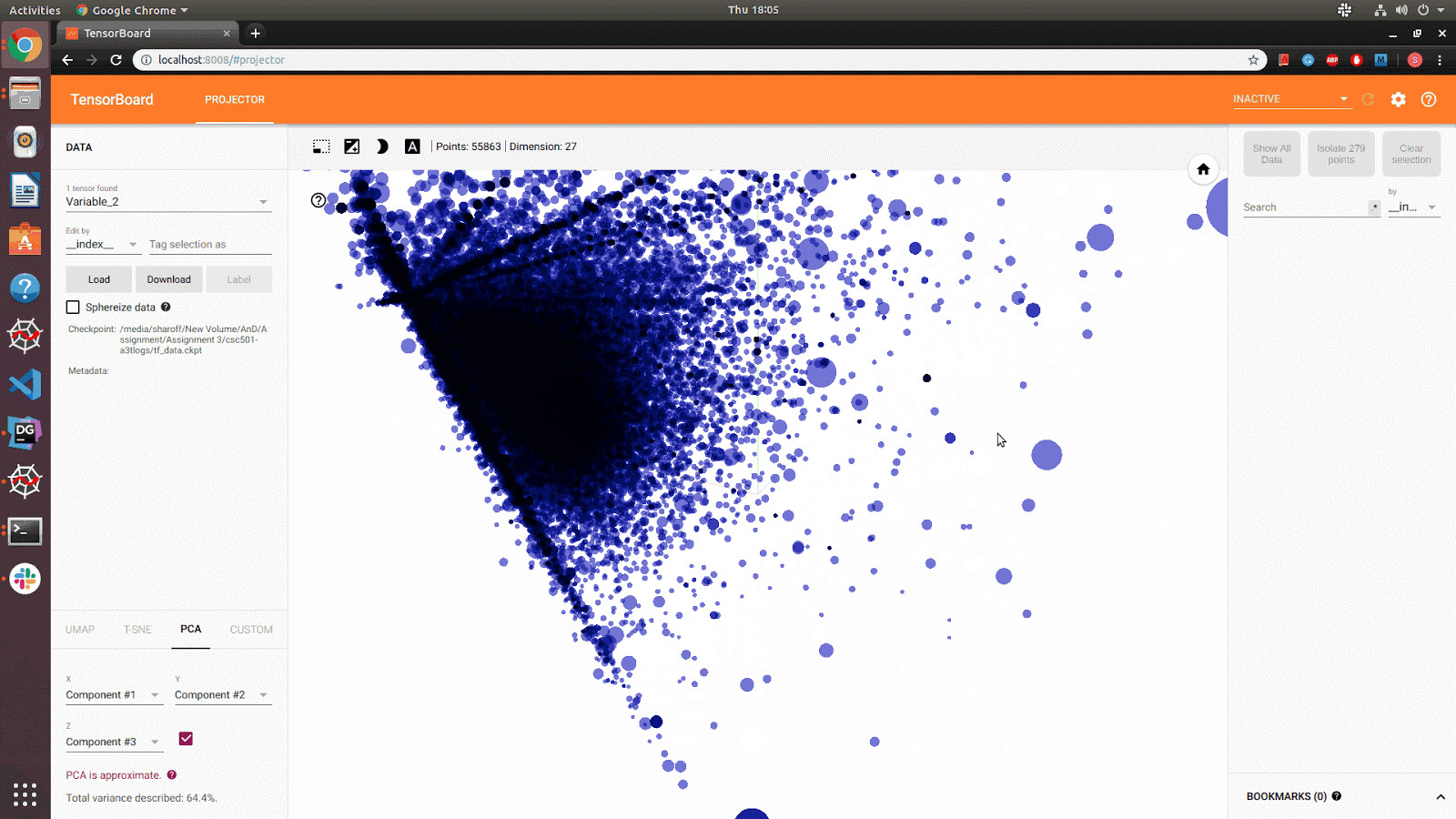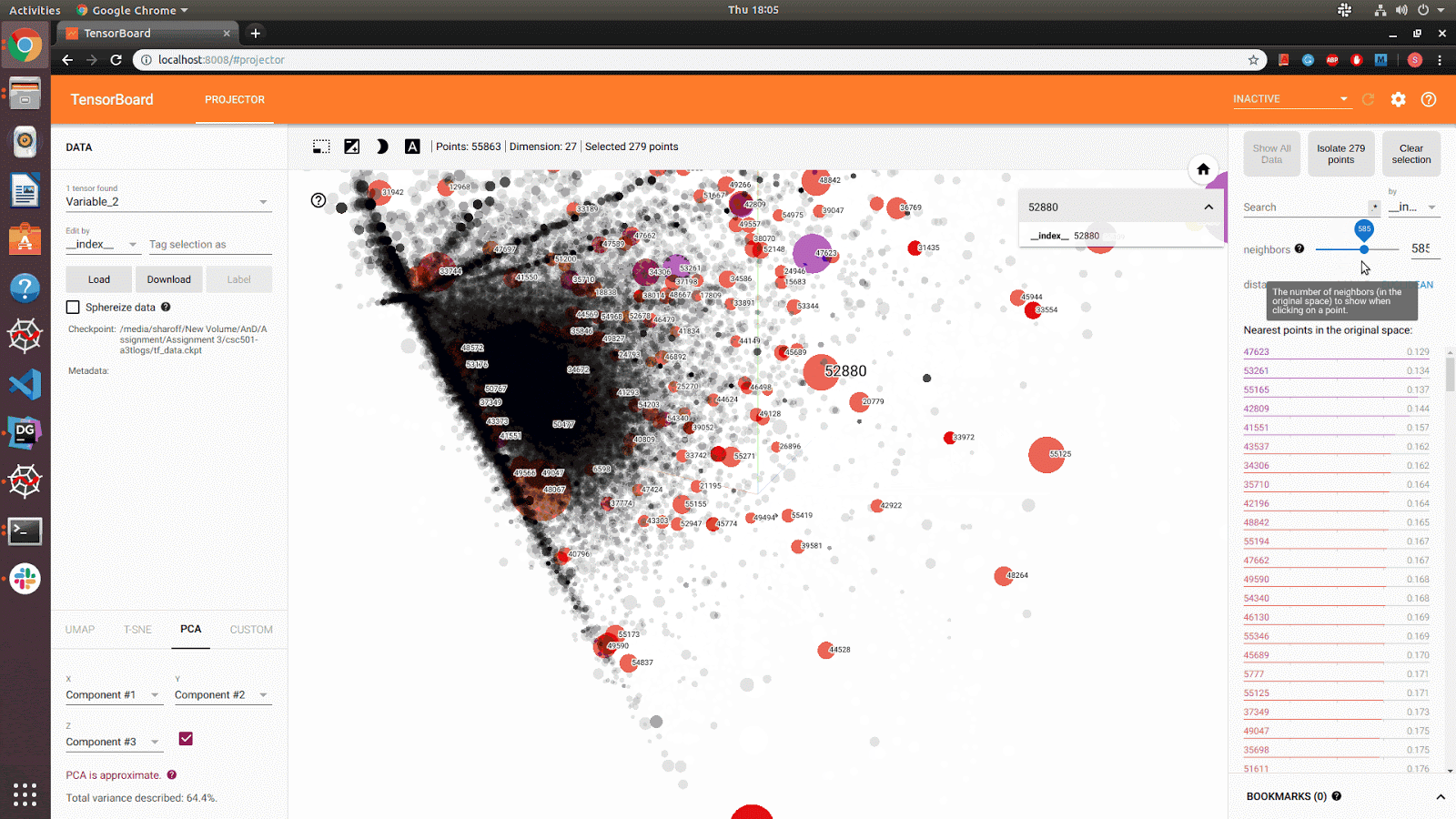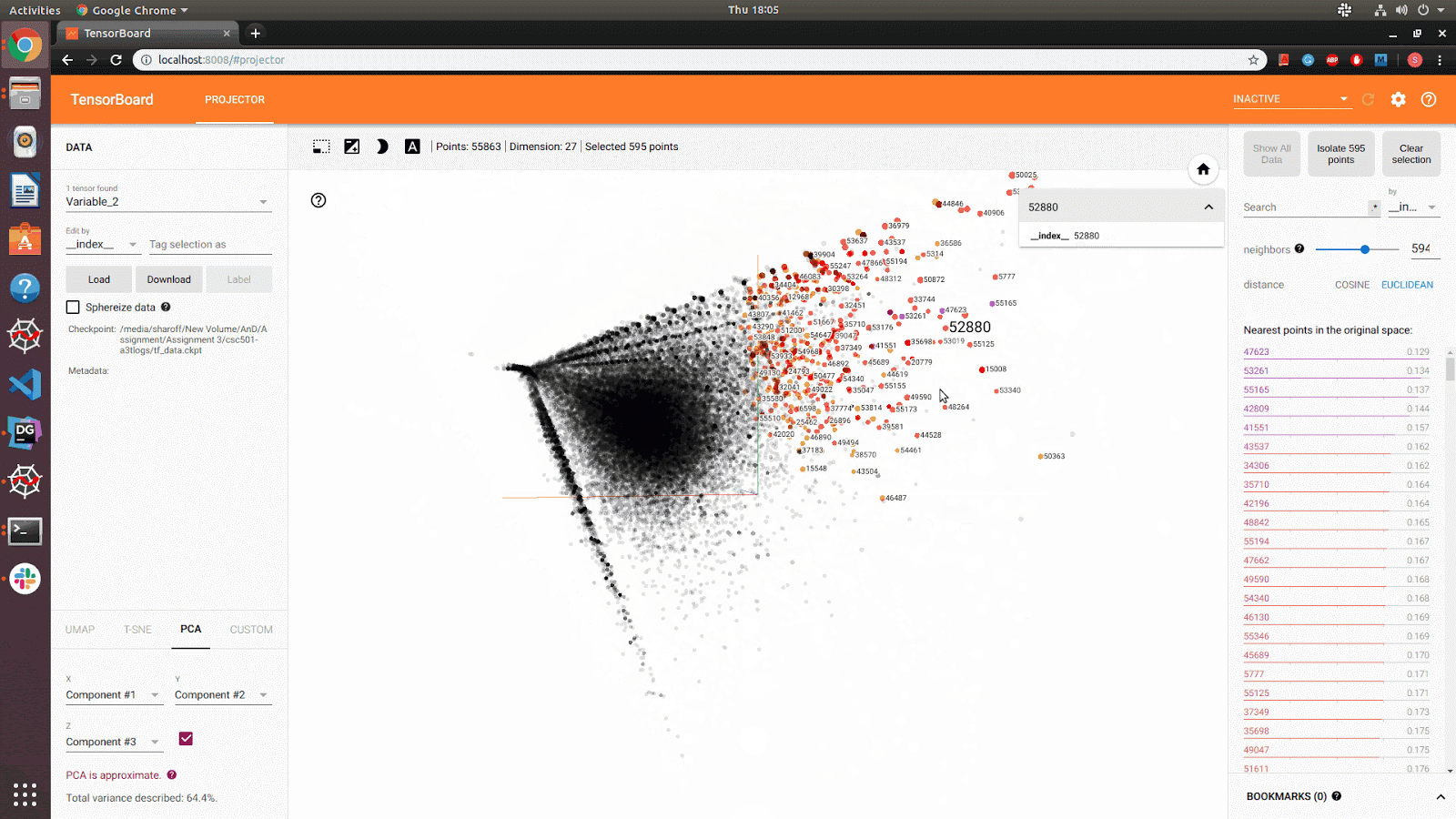
Data: SNAP: reddit-hyperlink graph (55863 nodes[subreddits] and 858490 edges[hyperlinks])
Technologies: PostgreSQL, psycopg2, Neo4j, snap.py, graphviz, Tensorflow, Tensorboard, Python etc.
Social Network: Reddit Hyperlink Network dataset is treated as a directed graph, and intially Neo4j was used for graph modelling. Upon further analysis, The data models were designed to model graph data while taking advantage of the relational model by storing the data as an edge list, better representing the relationships present in connections between nodes (subreddits). This allowed reduced cost of operation, easy relationship analysis and provided the opportunity to take advantage of other relational constraints, such as uniqueness of data. From the edge list we used snap.py to convert the edge list to a graph object, From the graph object we used graphviz for image rendering. The well connected subreddits were found by their connection strength and word count. Also, it is evident from the data that, most of the connections represent trolling references spreading negativity. To improve personized experience, an NSFW/ Child Filter was built by using the sentimental features. Also, closely related subreddits were identified (for recommendation) to better improve the user experience.
New York Taxi Data set
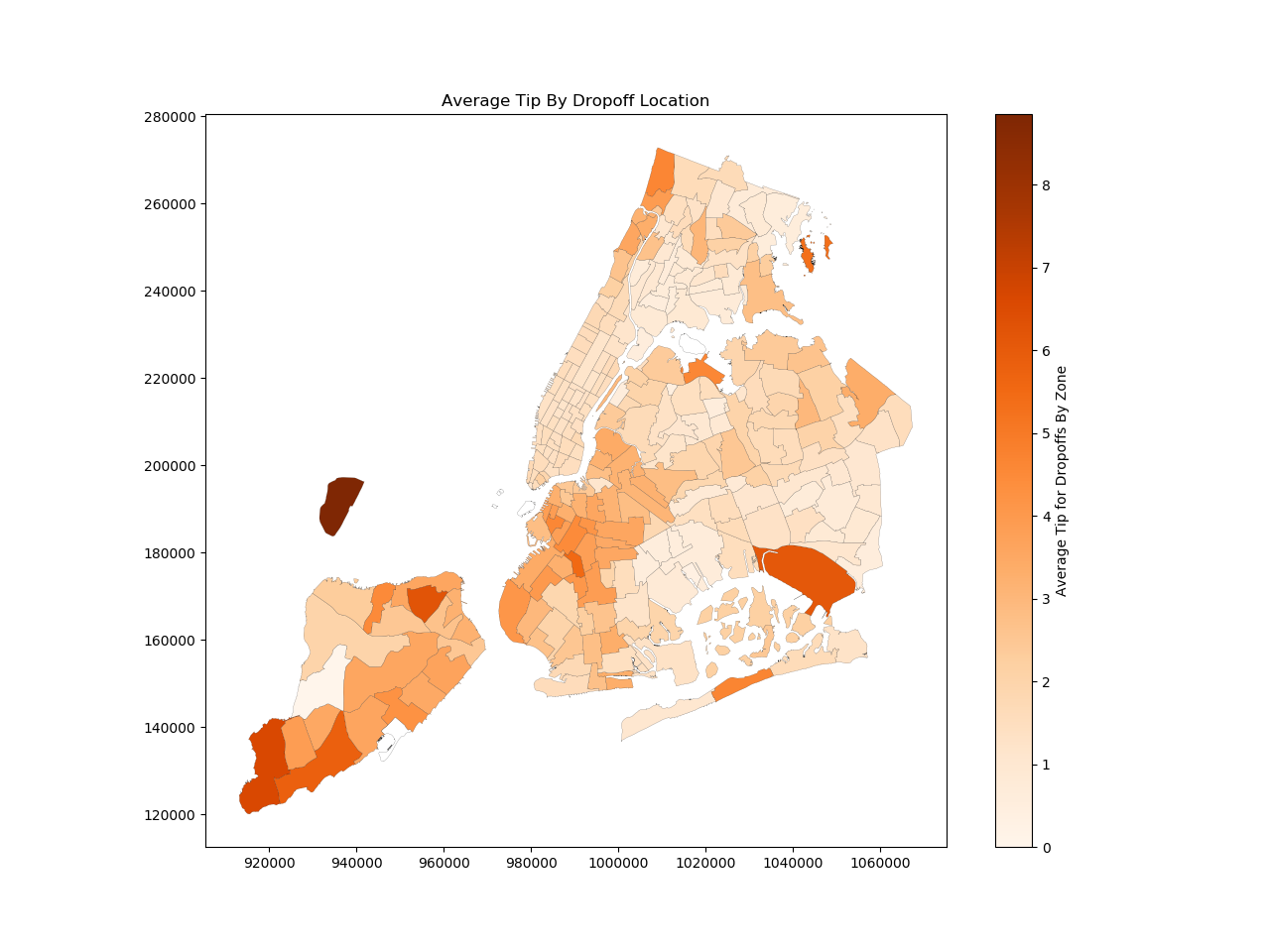
Tags: Spacial-Temporal data Modelling, Relational DB
Data: NYC taxi trip data set
Technologies: PostgreSQL, psycopg2, pyshp, Python etc.
The NYC taxi dataset has records of NYC yellow taxi rides with relevant trip information including geo spatial location (pickup/ drop-off location) and temporal (time of pickup/ drop-off). To facilitate information retrivel in dataset of this scale, a computationally efficient data modelling was carried out by taking advantage of relational database constraints and other database constraints (such as enforcing value ranges, informing the database of the requirement of the presence of or uniqueness of data). Shape models were used to render taxi zones and an aggregated center point model was created for minimizing nested loop calculations to a single run-through rather than a run-through on each visualization run. A Few interesting insights were obtained which could recommended top routes for a driver looking to maximize route frequency and tips, and minimize losses from refunds. Also, the frequency of trips in Manhattan, the northern half of Brooklyn, and airports were also shown graphically. A general cycle of routes is identified between the best airport (LaGuardia) and optimal zone locations (northern Brooklyn, outskirts of Manhattan), providing a new driver with the data necessary to get started. Also, recommendations for customer service improvements were also made.
Data Source Integration
Tags: Data Integration, Relational Data Model
Data: Movie Lens Dataset & IMDB
Technologies: PostgreSQL, psycopg2, Python
The MovieLens dataset contains records of ratings from different users for movies released over a period of time. To fully analyse and understand the public viewing patterns and other insights, the MovieLens dataset was Integrated with the largest movie dataset in the planet, IMDB data by designing relational data models that maximize space and time computational efficiency, taking full advantage of foreign relationships and database constraints. From this new data source, Insights in shift in users' viewing pattern, bias in the MovieLens dataset, viewerships based on genre, etc. were derived. To quickly, find the quality or watch ability of the movie once released, we gave weightage to the users whose average ratings were close to the general public (IMDB score) with some confidence interval and labelled them as power user to give proporate weightage based on their past ratings. This way, the convergence of new movie ratings to the actual quality of the movie can be retained quickly.